Build Infinity Scroll Using RxJS
Read more
Have you ever experienced slow loading or lag on a webpage while trying to load a large amount of data? If so, you're not alone. An effective solution to improve the experience is to use infinite scrolling, which works similarly to how your Twitter feed continuously loads more tweets as you scroll down.
A web design technique where, as the user scrolls down a page, more content automatically and continuously loads at the bottom, eliminating the user’s need to click to the next page.
Scroll down for the result, Or see the complete code
Using Angular? Here's a detailed implementation
Problem
Infinite scrolling is often used for a few key reasons:
-
Data Fetching: Loading large data sets all at once can lead to latency issues or even browser crashes.
-
Mobile Usability: On mobile platforms, scrolling is more intuitive than navigating through multiple pages.
-
Resource Optimization: Incremental data loading is generally more resource-efficient, reducing the load on both the server and the client, which can lead to faster load times and a better user experience.
Solution
You're going to build a minimal yet efficient function using RxJS. It will include:
- Support for vertical scrolling
- Horizontal scroll support for both LTR and RTL
- A threshold for determining when to fetch more data
- Loading state
The writing assumes you have a basic understanding of RxJS. No worries though, I'll explain any special code or RxJS features along the way. So get ready, because you're about to dive into some RxJS operators! 😄
For those already comfortable with RxJS, you can skip the next section or jump to The Code
Well, Let's start!
Getting Started
The only thing you need to get started is RxJS. Install it with this command:
npm i rxjsNote: I'm using TypeScript primarily for clarity in showing what options are available through types. You're free to omit them, but if you do want to use types, I'd suggest opting for a framework that has built-in TypeScript support.
RxJS operators
RxJS operators are functions that manipulate and transform observable sequences. These operators can be used to filter, combine, project, or perform other operations on an observable sequence of events.
Common RxJS Operators
There are a lot of them, most used (by me 😆) are tap, map, filter, switchMap, and finalize. You might already know how to use those but lucky you, we're going to learn about other useful operators!
Take a look at the following observable:
const source$ = from([1, 2, 3, 4, 5]);
source$.subscribe(event => console.log(event));The result would be 1 2 3 4 5. -Each in a new line-
filter
To only log odd numbers
const source$ = from([1, 2, 3, 4, 5]);
source$.pipe(filter(event => event % 2)).subscribe(event => console.log(event));Say there's a possibility that the source$ might emit a null value. You can use a filter to stop it from passing through the rest of the sequence.
const source$ = from([1, 2, 3, null, 5]);
source$
.pipe(filter(event => event !== null))
.subscribe(event => console.log(event));map
To change the sequence of events, you can use the map operator.
source$
.pipe(map(event => (event > 3 ? `Large number` : 'Good enough')))
.subscribe(event => console.log(event));What if I want to inspect an event without changing the source sequence
tap
source$
.pipe(
tap(event => {
logger.log('log an event in the console');
// you can perform any operation as well, however return statment are ignore in tap function
})
)
.subscribe(event => console.log(event));finalize
To monitor the end of an observable's lifecycle, you can use the finalize operator. It gets triggered when the observable completes.
It is usually used to perform some cleanup operations, stop the loading animation, or debug the memory, for example, add a log statement to ensure that the observable is complete and doesn't stuck in the memory 🥲.
debounceTime
Imagine you're building a login form and upon the user typing its password you want to hit the backend server to ensure the password conforms to certain criteria.
condt source$ = fromEvent(passwordInput, 'input').pipe(
map((event) => passwordInput.value),
switchMap((password) => checkPasswordValidaity(password))
)
source$.subscribe(event => console.log(event));This example might work fine with one key caveat; on every keystroke, a request is sent to the backend server, thanks to switchMap it'll cancel previous requests so there might not be as much harm, however, using debounceTime you can ignore input events till the dueTime -argument- is pass.
const source$ = fromEvent(passwordInput, 'input').pipe(
debounceTime(2000)
map((event) => passwordInput.value),
switchMap((password) => checkPasswordValidaity(password))
)
source$.subscribe(event => console.log(event));Adding debounceTime essentially implies creating 2 seconds between each keystroke, so a user enters "hello" and then before 2 seconds pass enters "world" and only one request will be sent. In other words, each event has to have a 2 seconds distance from the last event.
startWith
An observable might not have value immediately and you need an event readily available for the new source$ subscribers.
const defaultTimezone = '+1'
condt source$ = fromEvent(timezoneInput, 'input').pipe(
map((event) => timezoneInput.value),
startWith(defaultTimezone)
)
source$.subscribe(event => console.log(event));This sample will immediately log "+1" even if timezoneInput value is never entered
fromEvent
You could rewrite the previous example to be as follows
const timezoneInputController = new Subject<string>();
const timezoneInputValue$ = timezoneInputController.asObservable();
timezoneInput.addEventListener('input', () =>
subject.next(timezoneInputController.value)
);
const source$ = timezoneInputValue$.pipe(
map(event => event.target.value),
startWith(defaultTimezone)
);
source$.subscribe(event => console.log(event));Thanks to RxJS you can use fromEvent that will encapsulate that boilerplate, all you need to do is to say which event to listen to and from what element. Of course fromEvent returns an observable 🙂
takeUntil
I admit this one might be difficult to digest, it was for me. Taking the same previous example, Let's say that you have a form, an input, and a submit button. When the user clicks on the submit button you want to stop listening to the timezoneInput element input event. Yes, takeUntil as it sounds, it lets the subscribers take events until the provided observable emits at least once.
const defaultTimezone = '+1'
condt source$ = fromEvent(timezoneInput, 'input').pipe(
map((event) => timezoneInput.value),
startWith(defaultTimezone)
)
// normally, this subscriber will keep logging the event even if the users clicked on the submit button
source$.subscribe(event => console.log(event));
// Now, once the submit button are clicked the subscriber subscription will be canceled
const formSubmission$ = fromEvent(formEl, 'submit')
source$
.pipe(takeUntil(formSubmission))
.subscribe(event => console.log(event));pipe
The pipe function in RxJS is a utility for composing operations on observables. Use it to chain multiple operators together in a readable manner, or to create reusable custom operators. This is crucial when the source sequence is complex to manage.
import { pipe } from 'rxjs'; // add it to not to be confused with Observable.pipe
// Create a reusable custom operator using `pipe`
const doubleOddNumbers = pipe<number>(
filter(n => n % 2 === 1),
map(n => n * 2)
);
const source$ = from([1, 2, 3, 4, 5]);
source$.pipe(doubleOddNumbers).subscribe(x => console.log(x));
// result: 1, 6, 10Flattening Operators
Sometimes, you need to fetch some data with every incoming event, say from the backend server. There are a few methods to do this.
switchMap
Like a regular map, the switchMap operator uses a project function that returns an observable -its first argument-, known as the inner observable. When an event occurs, switchMap subscribes to this inner observable, creating a subscription that lasts until the inner observable completes. If a new event arrives before the previous inner observable completes, switchMap cancels the existing subscription and starts a new one. In other words, it switches to a new subscription.
const source$ = from([1, 2, 3, 4, 5]);
function fetchData(id: number) {
return from(fetch(`https://jsonplaceholder.typicode.com/todos/{id}`));
}
source$
.pipe(switchMap(event => fetchData(event)))
.subscribe(event => console.log(event));In this sample, only the todo with id 5 will be logged because switchMap works by switching the priority to the recent event as explained above. from([...]) will emit the events after each other immediately thereby switchMap will switch (subscribe) to the next event inner observable as soon as it arrives without regard to the previous inner observable subscription. The switch operation essentially means unsubscribing from the previous inner observable and subscribing to the new one.
concatMap
It blocks new events from going through the source sequence unless the inner observable completes. It is particularly useful for database writing operations or animating/moving an element where it's important to complete one action before starting another.
source$
.pipe(concatMap(event => fetchData(event)))
.subscribe(event => console.log(event));This sample will log all todos in order. Essentially what happens is concatMap blocks the source sequance till the inner observable at hand completes.
mergeMap
It doesn't cancel the previous subscription nor blocks the source sequence. mergeMap will subscribe to the inner observable without regard to its completion, so if an event comes through and the previous inner observable hasn't been completed yet that's fine, mergeMap will subscribe to the inner observable anyway.
source$
.pipe(mergeMap(event => fetchData(event)))
.subscribe(event => console.log(event));This sample will log all todos but in uncertain order, for instance, the second request might resolve before the first one and mergeMap doesn't care about the order, If that is important then use concatMap.
exhaustMap
The final one and the most important in this writing is exhaustMap: it is like switchMap but with one key difference; it ignores the recent events in favor of the current inner observable completion in contrary to switchMap which cancels the previous inner observable subscription in favor of a new one.
source$
.pipe(exhaustMap(event => fetchData(event)))
.subscribe(event => console.log(event));This sample will only log the first todo as the first todo request hasn't been completed yet other events came through therefore they've been ignored.
To summarise
switchMapwill unsubscribe from the existing subscription (if the previous inner observable hasn't been completed) in favor of a new one when a new event arrives.concatMapwill block the source sequence so the inner observable at hand must be complete before allowing other events to flow.mergeMapdoesn't care about the status of the inner observable so it'll subscribe to the inner observable as events come through.exhaustMapwill ignore any event till the current inner observable is complete.
Okay, that is a lot, isn't it? I understand that if you're new to RxJS you might not be able to digest all this info, Your best bet is to practice and that's what you're trying to do here.
Wow, I really did it, and you did too 😎
Time to talk about some of the Scroll API(s)
Scroll API
You already know the Scroll Bar, it's at the right end of the page 🥸, no really, when the user scroll in any direction the browser emits a few events, like scroll, scrollend, and wheel.
You are going to learn enough that to tackle the problem at hand.
Let's start with scroll and scrollend:
Scroll and ScrollEnd Events
The scroll event fires while an element is being scrolled and scrollend fires when scrolling has completed.
element.addEventListener('scroll', () => {
console.log(`I'm being scrolled`);
});
element.addEventListener('scrollend', () => {
console.log(`User stopped scrolling`);
});Keep in mind that this only works if the element—the one that has the event listener (handler)—is scrollable, not its parent or any ancestor or descendant elements.
Wheel Event
The wheel event fires while an element or any of its children is being scrolled using the mouse/trackpad wheel which means trying to scroll down/up using the keyboard won't trigger it.
Size Properties
For the task at hand, the scroll event will be the primary focus. However, I've also outlined some additional events and properties to give you a well-rounded understanding. Now, let's look at the key size properties you'll need to know:
element.clientWidth: The inner width of the element, excluding borders and scrollbar.element.scrollWidth: The width of the content, including content not visible on the screen. If the element is not horizontally scrollable then it'd be the same asclientWidth.element.clientHeight: The inner height of the element, excluding borders and scrollbar.element.scrollHeight: The height of the content, including content not visible on the screen. If the element is not vertically scrollable then it'd be the same asclientHeight.element.scrollTop: The number of pixels that the content of an element is scrolled vertically.
Note: When I say "the content," I mean the entirety of what's contained within the HTML element.

Let's take the following example, Calculate the remaining pixels from the user's current scroll position to the end of the scrollable element.
function calculateDistanceFromBottom(element: HTMLElement) {
const scrollPosition = element.scrollTop;
const clientHeight = element.clientHeight;
const totalHeight = element.scrollHeight;
return totalHeight - (scrollPosition + clientHeight);
}Take a look at the below image.

Presuming the totalHeight is 500px, clientHeight 300px, and the scrollPosition is 100px, deducting the sum of scrollPosition and clientHeight from totalHeight would result in 100px which is the remaining distance to reach the bottom of the element.
A similar formula when calculating the remaining distance to the end horizontally
function calculateRemainingDistanceOnXAxis(element: HTMLElement): number {
const scrollPosition = Math.abs(element.scrollLeft);
const clientWidth = element.clientWidth;
const totalWidth = element.scrollWidth;
return totalWidth - (scrollPosition + clientWidth);
}Presuming the totalWidth is 750px, clientWidth 500px and the scrollPosition is 150px, deducting the sum of scrollPosition and clientWidth from totalWidth would result in 100px which is the remaining distance to reach the end of the XAxis.
You might have noticed the Math.abs being used and that due to RTL direction where the user has to go in the reverse direction which would make the scrollPosition value to be negative so using Math.abs to unify it in both directions.

Side tip: Using the information you have about the element's sizes, you can also make a function to check if the element can be scrolled or not.
type InfinityScrollDirection = 'horizontal' | 'vertical';
function isScrollable(
element: HTMLElement,
direction: InfinityScrollDirection = 'vertical'
) {
if (direction === 'horizontal') {
return element.scrollWidth > element.clientWidth;
} else {
return element.scrollHeight > element.clientHeight;
}
}Simply put, if the element scroll's size is the same as its client's size then it isn't scrollable.
The Code
I know you've been looking around to find this section, finally, we'll put all the learnings into action, let's start by creating a function named infinityScroll that accepts options argument
export interface InfinityScrollOptions<T> {
/**
* The element that is scrollable.
*/
element: HTMLElement;
/**
* A BehaviorSubject that emits true when loading and false when not loading.
*/
loading: BehaviorSubject<boolean>;
/**
* Indicates how far from the end of the scrollable element the user must be
* before the loadFn is called.
*/
threshold: number;
/**
* The initial page index to start loading from.
*/
initialPageIndex: number;
/**
* The direction of the scrollable element.
*/
scrollDirection?: InfinityScrollDirection;
/**
* The function that is called when the user scrolls to the end of the
* scrollable element with respect to the threshold.
*/
loadFn: (result: InfinityScrollResult) => ObservableInput<T>;
}
function infinityScroll<T extends any[]>(options: InfinityScrollOptions<T>) {
// Logic
}As promised, you now can customize the infinite scroll function to your liking. Next, you'll learn how to attach an event listener to the specific element that contains your infinitely scrollable list of items.
function infinityScroll<T extends any[]>(options: InfinityScrollOptions<T>) {
return fromEvent(options.element, 'scroll').pipe(
startWith(null),
ensureScrolled,
fetchData
);
}fromEventlistens toscrollevent of the scrollable element.startsWithstarts the source sequence to fetch the first batch of data.ensureScrolledis a chainable operator that confirms the scroll position surpasses the predefined threshold before proceeding.fetchDatais another chainable operator that fetches data based on thepageIndex, more on that later.
ensureScrolled
const ensureScrolled = pipe(
filter(() => !options.loading.value), // ignore scroll event if already loading
debounceTime(100), // debounce scroll event to prevent lagginess on heavy scroll pages
filter(() => {
const remainingDistance = calculateRemainingDistance(
options.element,
options.scrollDirection
);
return remainingDistance <= options.threshold;
})
);
function calculateRemainingDistance(
element: HTMLElement,
direction: InfinityScrollDirection = 'vertical'
) {
if (direction === 'horizontal') {
return calculateRemainingDistanceOnXAxis(element);
} else {
return calculateRemainingDistanceToBottom(element);
}
}filteronly passes the scroll events if the element is scrollable, otherwise, it might lead to unexpected behavior.debounceTimewill skip any event, in our case scroll events from flowing the sequencefilteris checking if theremainingDistanceeither to the bottom (in case of vertical scrolling) or to the end of XAxis in case of horizontal scrolling is less than thethreshold. Presumingthresholdis 100px then when the scroll position is within 100 pixels of reaching the end (either vertically or horizontally, depending on the configuration), loadMore.next() will be invoked, signaling that more content should be loaded.
fetchData
const fetchData = pipe(
exhaustMap((_, index) => {
options.loading.next(true);
return options.loadFn({
pageIndex: options.initialPageIndex + index,
});
}),
tap(() => options.loading.next(false)),
// stop loading if error or explicitly completed (no more data)
finalize(() => options.loading.next(false))
);exhaustMapignores any event till theloadFncompletes. IfexhaustMapproject function (its first argument) has been called, that implies the previous (if any) observable is completed and is ready to accept new events -load more data-.tapis signaling data loading is finished.finalizedoes the same as tap in our case, however,tapwon't be called ifloadFn-request to the backend server- had responded with an error, and in case of an error, the source observable completes hencefinalize. In other words, if the source sequence errored or the user explicitly completed the source then stop the loading.
Notice how exhaustMap indicates the loading state. You might question why not place the loading signal in a tap operator right before exhaustMap. Doing so would cause the loading observable to emit true whenever loadMore triggers. But this doesn't necessarily mean it's time to load more data -the previous inner observable from loadFn hasn't finished yet-. To avoid this, exhaustMap is used to confirm that it's ready to load more data.
The real piece of code; incrementing the page index to fetch the next patch of data
exhaustMap((_, index) => {
// ...code
return options.loadFn({
pageIndex: options.initialPageIndex + index,
// ...code
});
});The exhaustMap project function has two arguments
- The event from the source sequence.
- The index corresponds to the most recent event (this number signifies the position of the latest event).
In this specific case, you'll be focused on the event position or index. Check out the following example for a clearer understanding of how it operates.
- At first time the source
loadMoreemits theindexwill be zero. - 3 batches of data are loaded, so the next
indexwill be 4. - Assuming
initialPageIndexis 1 and the data is to be loaded for the first time then thepageIndexis 1 - Assuming
initialPageIndexis 1 and the data is to be loaded for the fifth time then thepageIndexis 6 - Assuming
initialPageIndexis 4 and the data is to be loaded for the first time then thepageIndexis 4
The last case might be off; usualy you might have initialPageIndex 0, but let's say you're scrolling the Twitter feed, and for some reason, the browser reloaded, so instead of loading data from the beginning, you decided to store the pageIndex in some state (URL query string) so in such cases only the data from the last pageIndex will be there so the experience continues as if nothing happened. Prior data needs to be there as well either by loading it till the pageIndex or via implementing an opposite scroll direction data loading 🥲
Example
Vertical Scrolling
{% embed https://codepen.io/ezzabuzaid/embed/preview/BavLOLp %}
Horizontal Scrolling
{% embed https://codepen.io/ezzabuzaid/embed/preview/oNJzPGN %}
RTL Horizontal Scrolling
{% embed https://codepen.io/ezzabuzaid/embed/preview/gOZwdXg %}
UX and Accessibility Consideration
Infinite scrolling isn't a magic fix. I know some folks who strongly advise against using it. Here's why:
-
Bad for Keyboard Users: If you're using a keyboard to get around a website, infinite scrolling can mess that up and get you stuck.Especially if the infinity scrolling is the main way of navigating the website
-
Hard to Pick Up Where You Left Off: Without page numbers, it's tough to go back to where you were. This makes it hard for users and a headache for developers to implement.
-
Unreachable Content: Makes certain content like footers hard to reach.
-
Confusing Screen Readers: If someone's using a screen reader, the constant loading can make the page structure confusing.
-
Too Much, Too Fast: For some people, like those who get easily distracted, the never-ending flow of content can be overwhelming. This one's just my take, but it's something to think about.
When building an infinite scroll you've to consider important factors such as:
- Placing content correctly and making them accessible like footer, and contact information.
- Allowing users to return to their previous spot.
- Offering the ability to jump ahead.
- Ensuring the experience is navigable for users who rely solely on keyboards.
I recognize that these tasks present significant developmental challenges. However, as the saying goes, quality comes at a cost.
This isn't to say that infinite scrolling is bad; instead, the emphasis is on applying it with caution.
Other Pagination Strategies
-
Traditional Pagination: This approach uses a combination of numbered pagination and 'Previous'/'Next' buttons to offer both specific and sequential page access.
-
"Load More" Button: Includes a button at the end of the visible content; clicking it appends additional items to the list.
-
Content Segmentation: Utilizes tabs or filters to categorize content, enabling quick navigation to topic-specific data—e.g., segmenting tweets into categories like Science, Tech, Angular, 2021, etc.
Bonus: What About Other Flattening Operators?
What about using mergeMap, switchMap, or concatMap? You might have thought about that already!
Given the following scenario: A user scrolled down to the end of the page, but the request to load more data is still pending. The user kept scrolling down to the end of the page but the data was not yet resolved. What do you think would happen?
Note: The following recordings use a slow 3g network speed
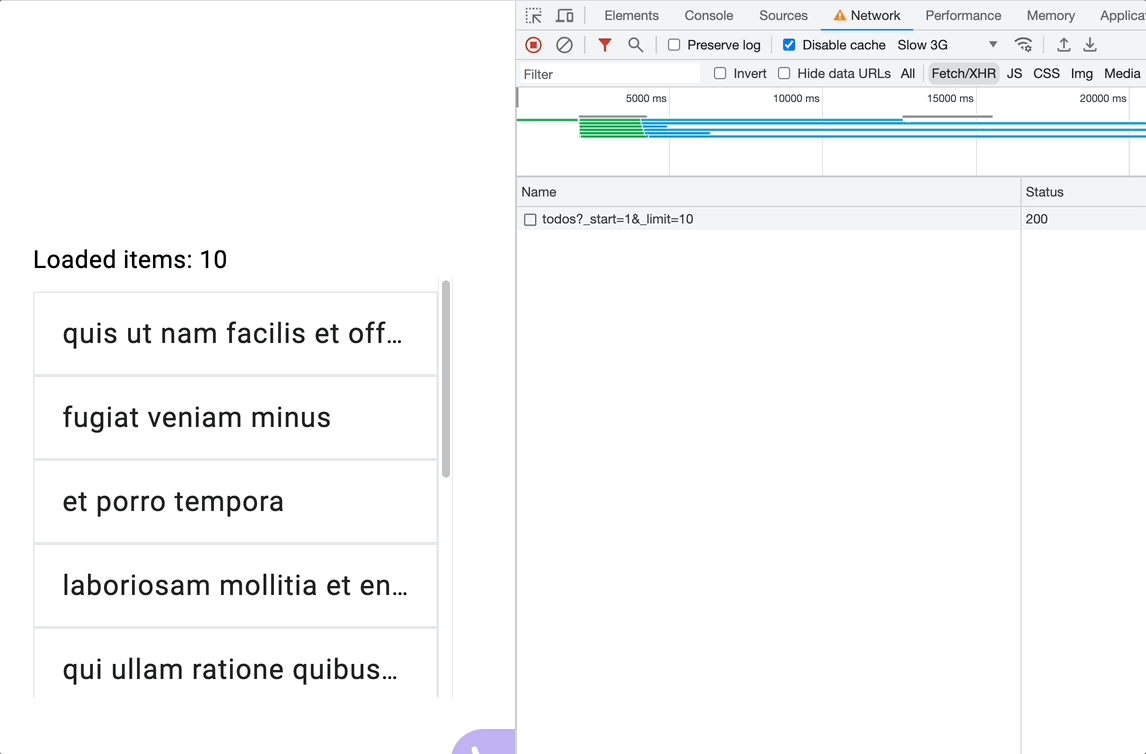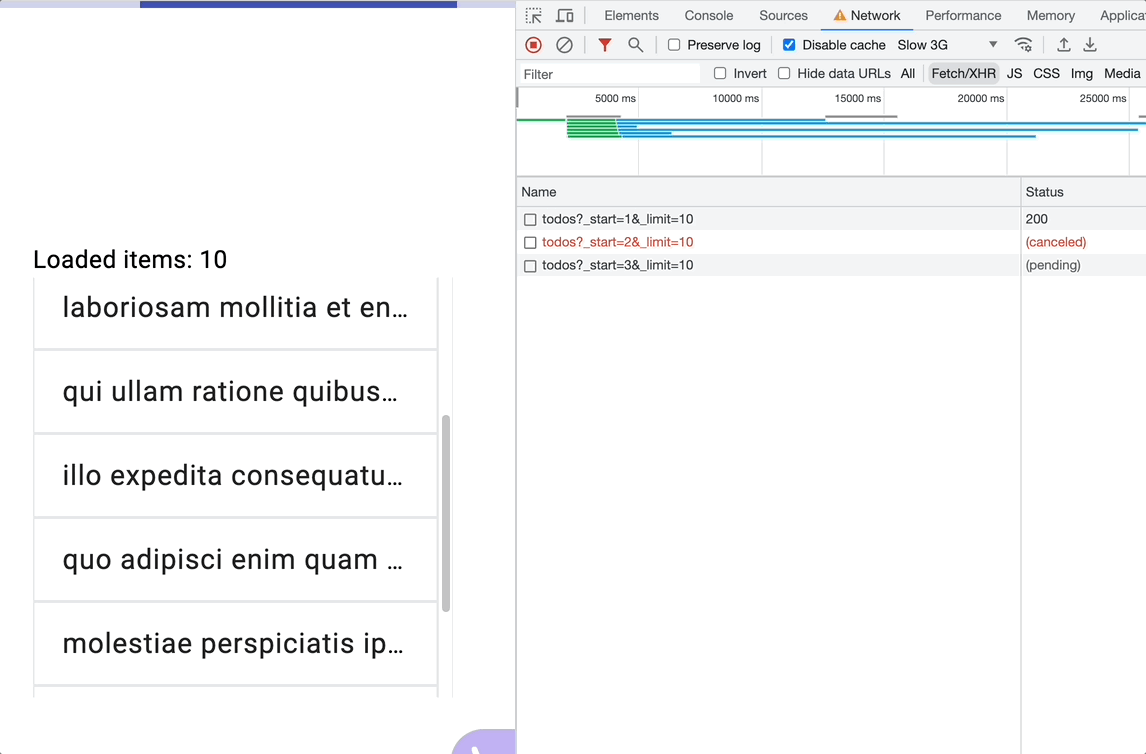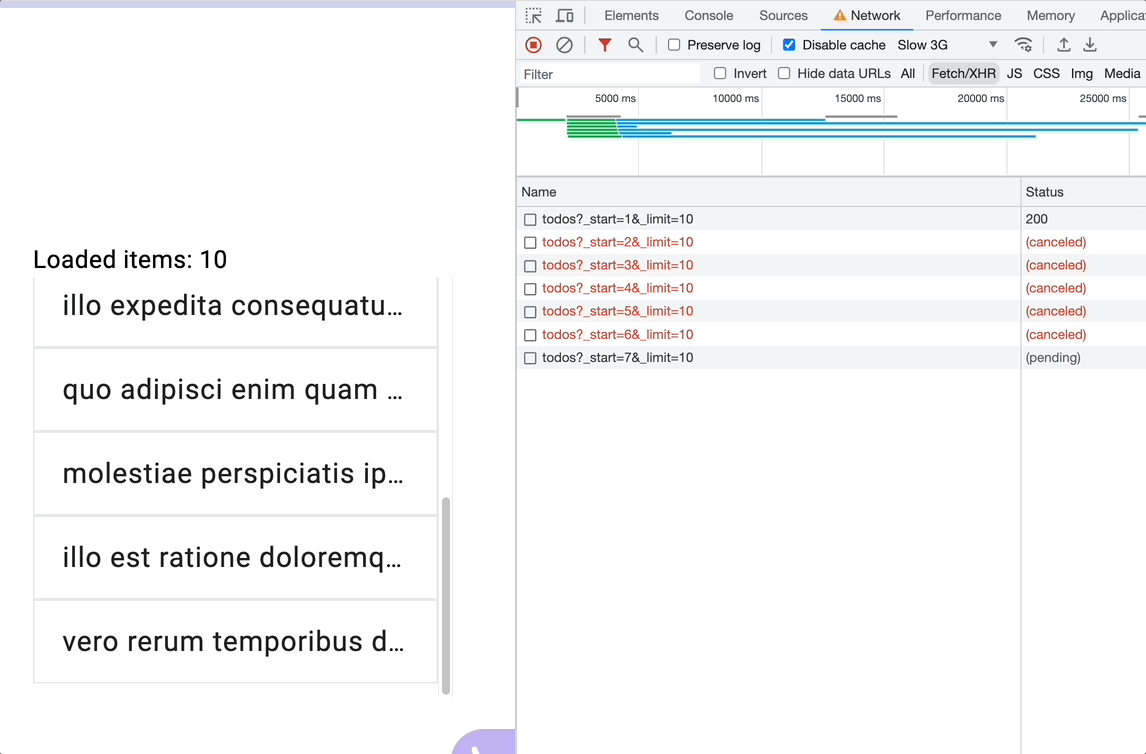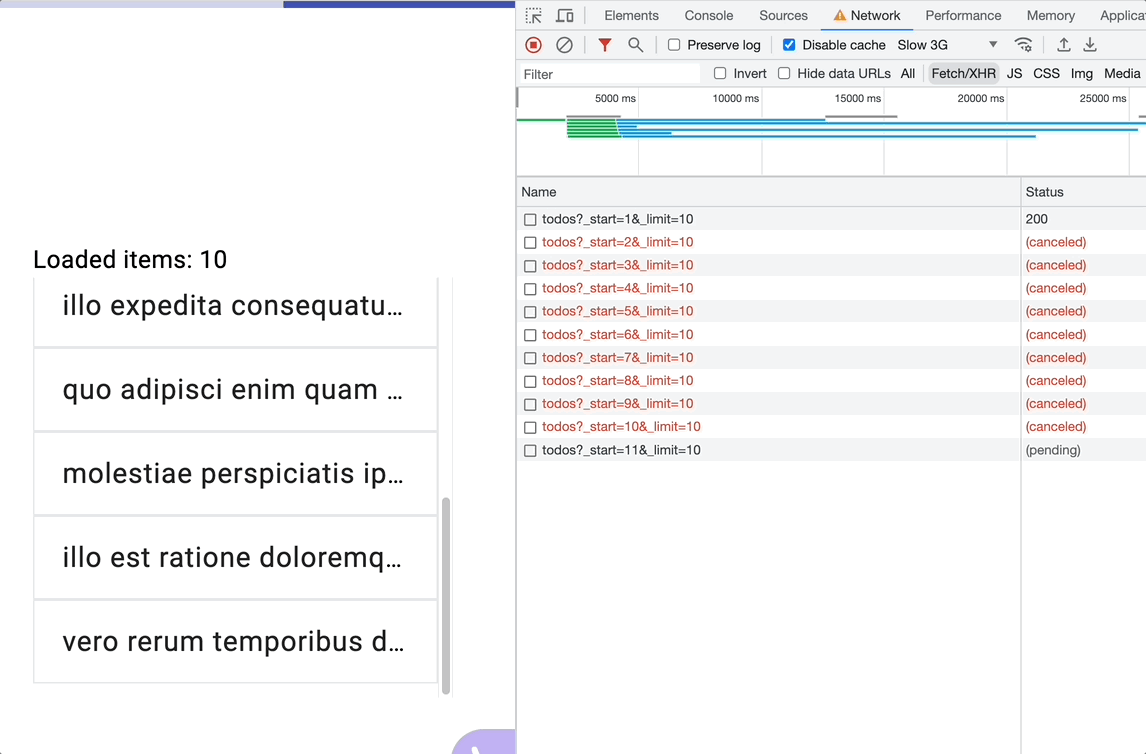
Using mergeMap
With each scroll event, mergeMap subscribes to the inner observable without regard to the previous subscription, essentially leading to a new request -loadMode- with each verified scroll event -below the threshold-
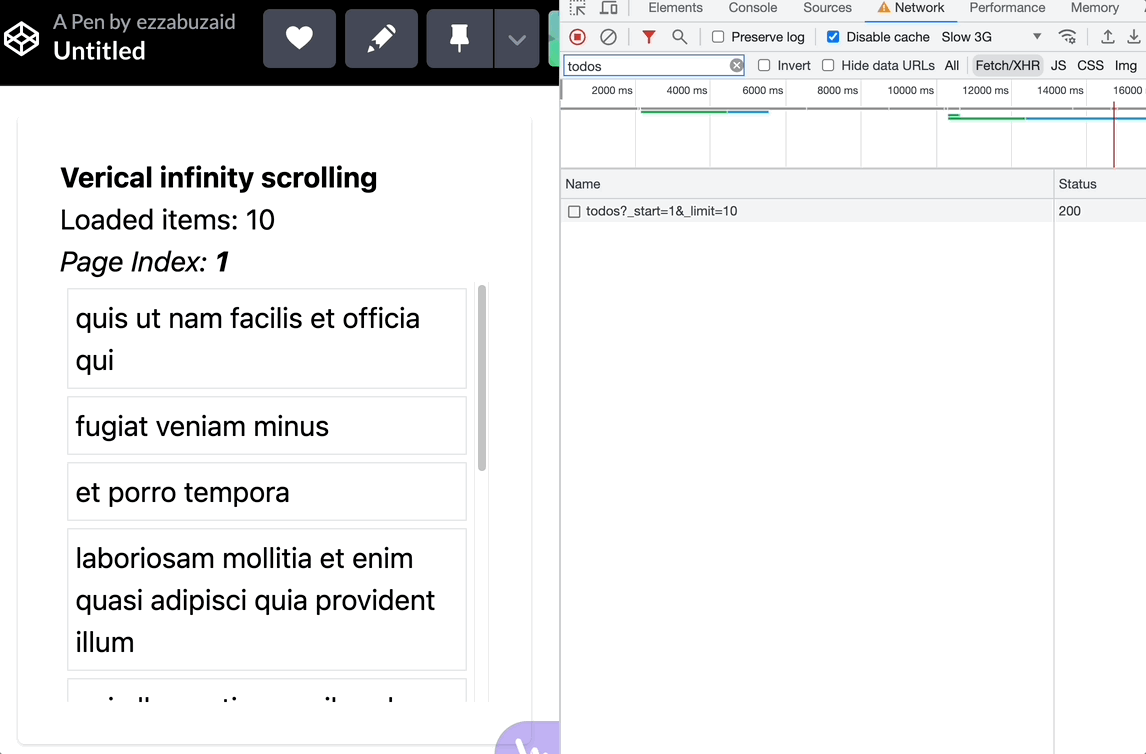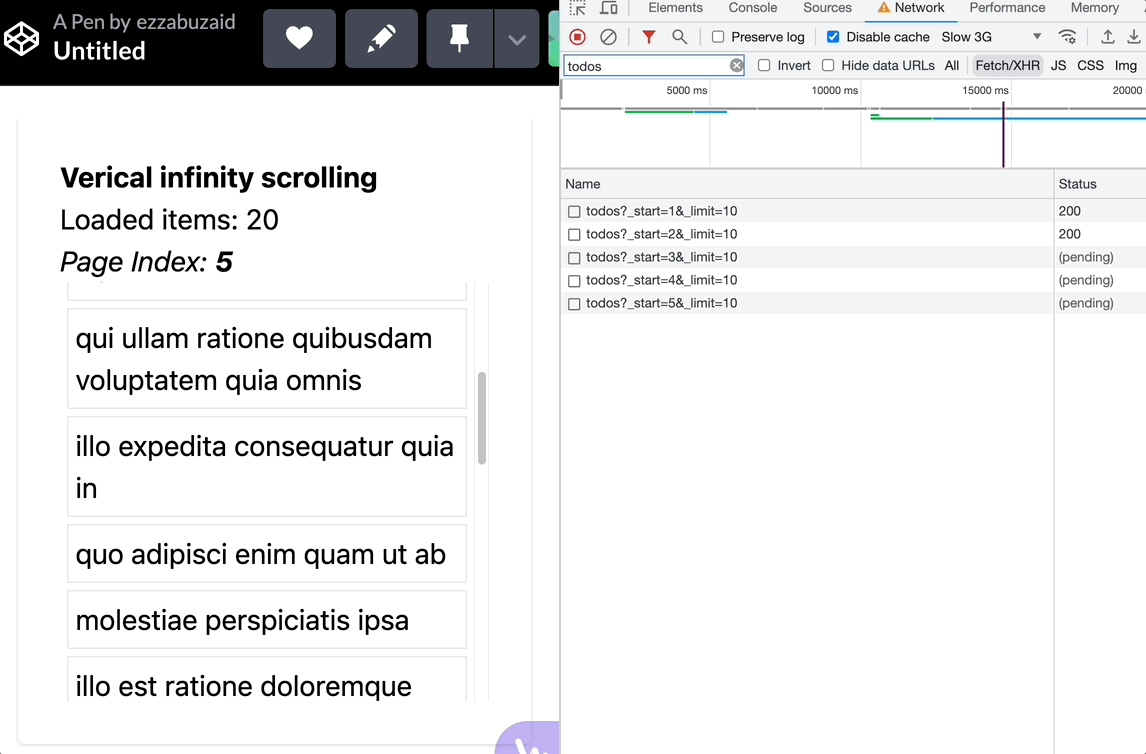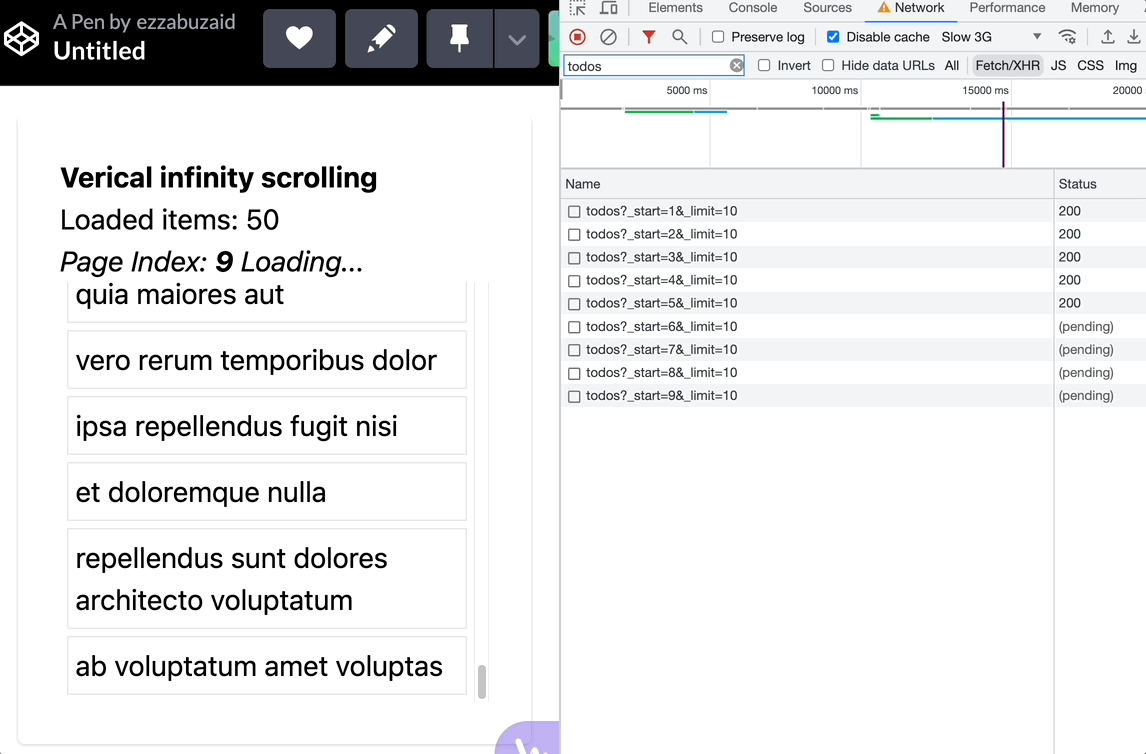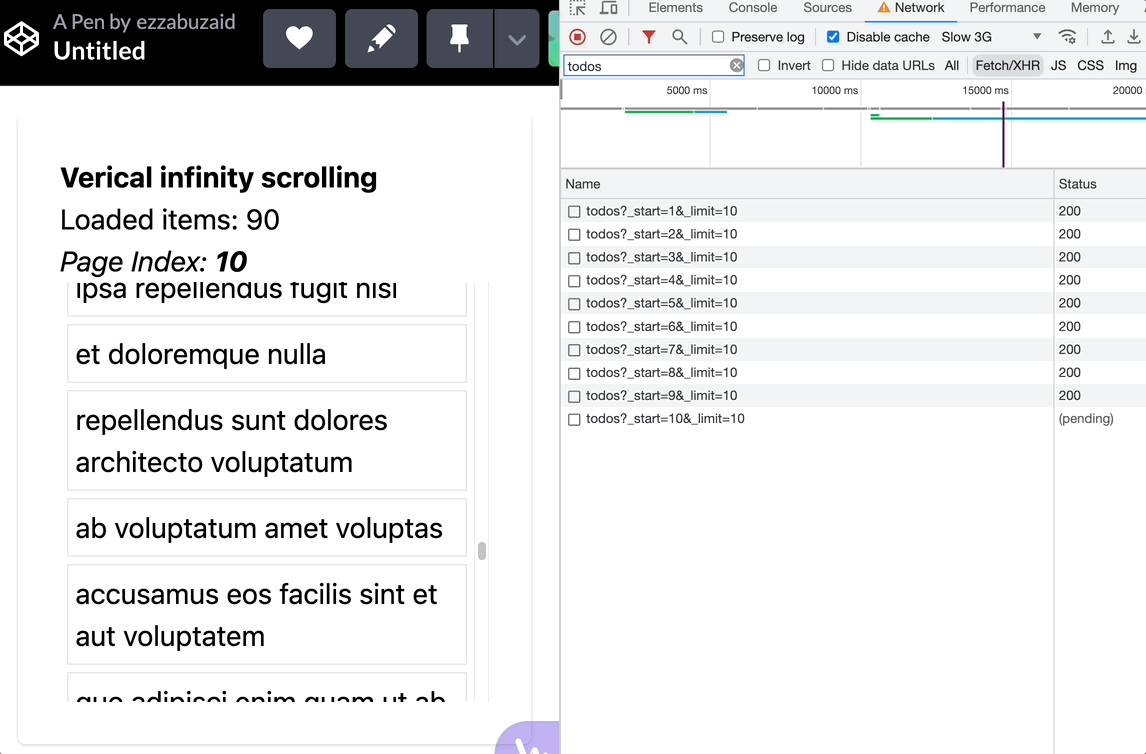
Using switchMap
With each scroll event, switchMap will cancel/unsubscribe from the previous subscription and subscribe to the inner observable again, essentially leading to a new request but the previous unresolved one will be canceled so only one request will be pending at a time. That might be okay, however, the event position index will increment each time switchMap subscripes to the inner observable which leads to incorrect data being loaded.
Using concatMap
With each scroll event, concatMap will subscribe to the inner observable, blocking the source sequence till the current subscription completes -loadMore request resolves-, essentially leading to a new request with every verified scroll but holding them onto till it can process a new event. The event position index will increment each time concatMap subscribes to the inner observable which leads to requesting more data than needed. See the recording below and take a good look at what happens in the Network Tap when the user stops scrolling.
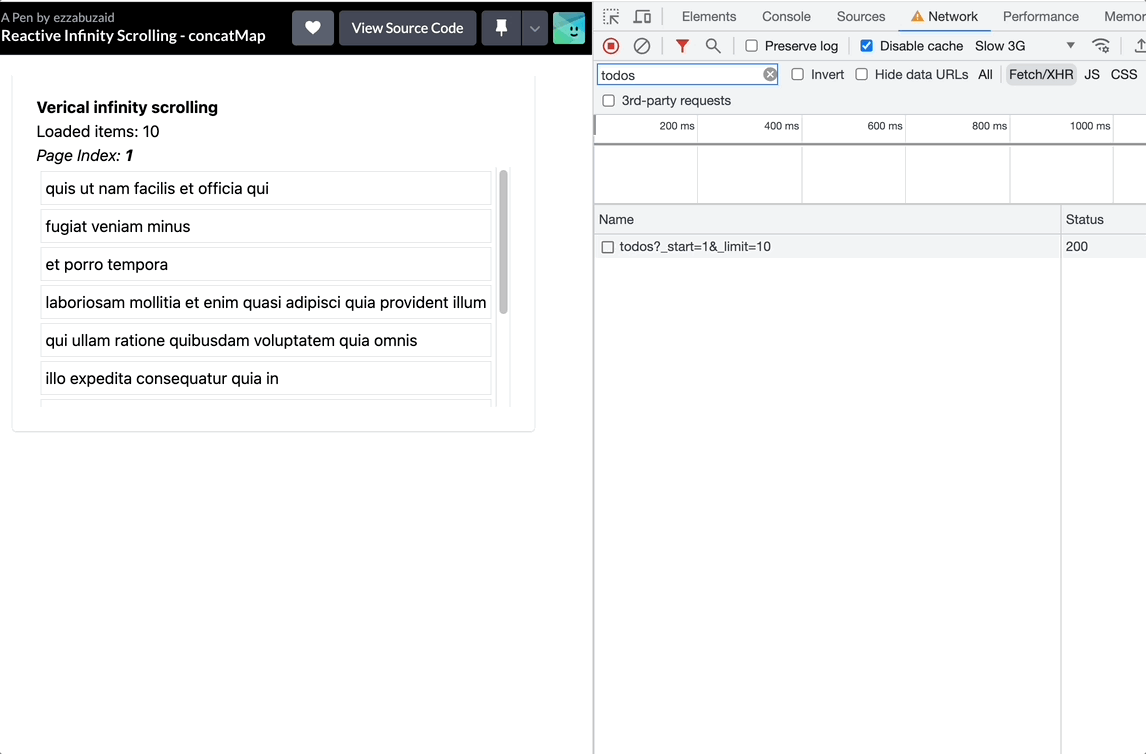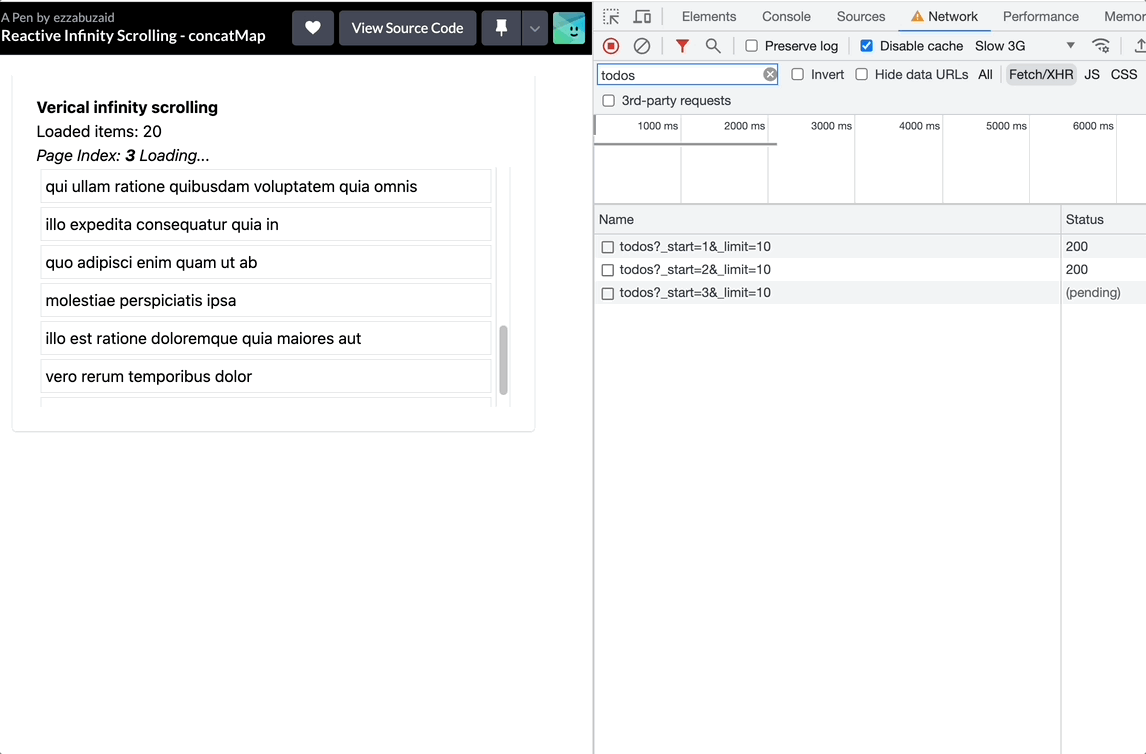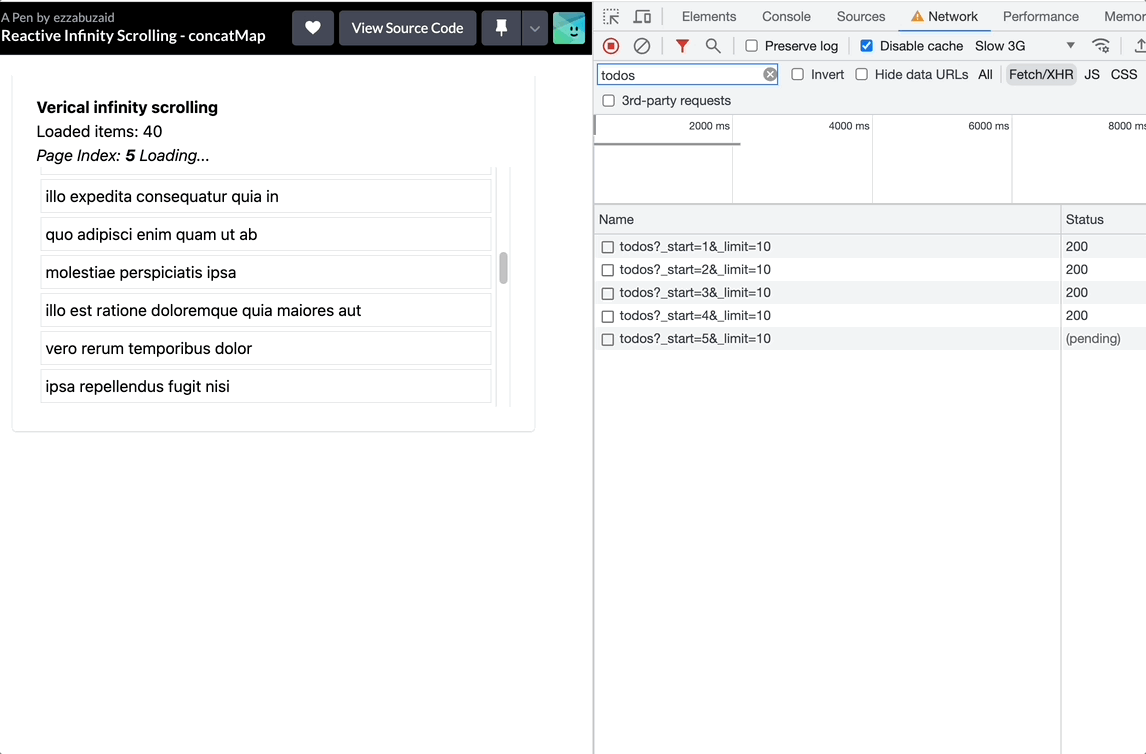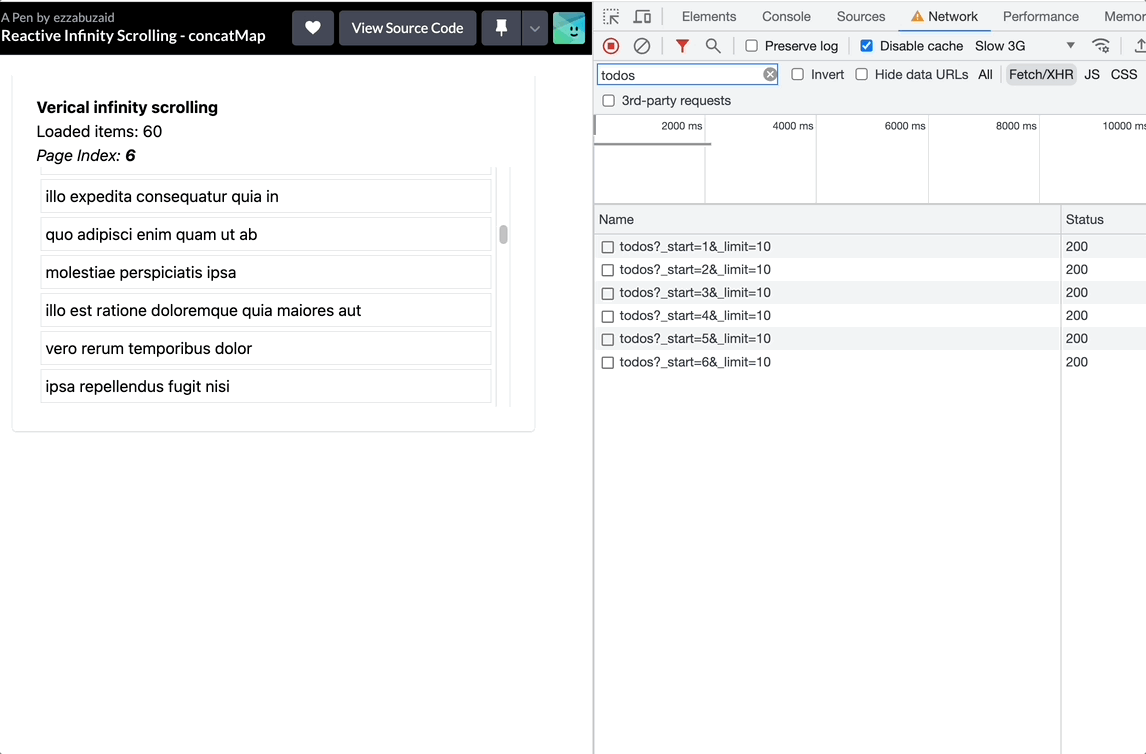
Using exaustMap
It is the winner in this scenario because it effectively manages pending requests. When a scroll event triggers a new request, exhaustMap will ignore any subsequent scroll events until the current request (inner observable) is complete. This ensures that only one request is pending at a time, and it prevents the index from incrementing incorrectly.
That being said, a simple workaround would be to explicitly ignore any scroll even while the data is loading.
const fetchData = pipe(
filter(() => options.loading.value === false),
// mergeMap, switchMap and concatMap should work now.
exaustMap((_, index) => {
// ...
})
// ...
);However, this approach has a limitation. Since options.loading is a user-defined observable, there's a risk that the user might change its value. If that happens, the issue will appear.
Next Step
In addition to the core functionality, further enhancements can be incorporated
- Resume Journey: An option to store the pageIndex to resume the user journey, history API for instance.
- Error Recovery: retry loading data when the operation fails. Although I think it shouldn't be part of the infinity scroll function, you can provide it as an option.
- Load more data when scrolling up: Imagine you navigate to a profile page and then go back to the feed, like on Twitter. The last page index could be saved in the history API, guiding what to fetch next. But what if you can't load all the earlier data at once? In that case, you can also load more content when the user scrolls up, not just when scrolling down.
- Improve performance by integrating Virtual Scrolling to only render visible elements.
Summary
Congrats! You've learned how to implement infinite scrolling and gained a deep understanding of the RxJS operators that power this feature. Alongside the technical side, you've taken a critical look at the potential accessibility challenges that come with infinite scrolling, equipping you with a balanced view of its pros and cons.
This implementation is framework-agnostic, requiring only RxJS as a dependency. While TypeScript is used for type safety, it's not a hard requirement and can be easily omitted.
Stay tuned for an upcoming post on Virtual Scroll. Subscribe to the newsletter to get notified when it's published. Your feedback and opinions are highly valued, so feel free to share them.
References
- Infinite Scroll Advantages and Disadvantages: When to Use It and When to Avoid It
- Infinite Scroll UX Done Right: Guidelines and Best Practices
- Infinite Scroll & Accessibility! Is It Any Good?
- RxJS Operators
- Angular Implementation